įŲėŗ╦Ń×ķ╣½╣▓Ę■äš(w©┤)╠ß╣®┴╦ą┬Ą─╗∙ĄA(ch©│)įO(sh©©)╩®ŲĮ┼_Ż¼ŲõÅŖš{(di©żo)į┌╠ōöM╗»Łh(hu©ón)Š│ųą▀\ąą┤¾ęÄ(gu©®)─Żėŗ╦ŃĄ─╔ņ┐sąį║═┐╔ė├ąįĪŻļSų°įŲėŗ╦Ń└ĒšōĄ─░l(f©Ī)š╣Ż¼╣½ėąįŲėŗ╦Ń║═├µŽ“╠ōöMĮM┐Śā╚(n©©i)▓┐Ą─╦ĮėąįŲėŗ╦Ń│╔×ķā╔ĘN▓╗═¼Ą─æ¬(y©®ng)ė├ĘČ«ĀŻ¼─┐Ū░Ų¾śI(y©©)╝ēæ¬(y©®ng)ė├Ė³ĻP(gu©Īn)ūóĄ─╩Ū╦ĮėąįŲŻ¼Ųõ║¾┼_įŲ┤µā”įO(sh©©)éõųąöĄ(sh©┤)ō■(j©┤)ÄņöĄ(sh©┤)ō■(j©┤)▓ķįāĘ┤æ¬(y©®ng)╦┘┬╩Ą─Ė▀Ą═Ż¼╩Ū¾w¼F(xi©żn)Ų¾śI(y©©)╦ĮėąįŲ╝╝ąg(sh©┤)┐╔öU(ku©░)š╣ąį║═Ė▀ą¦ąįĄ─ųžę¬ųĖś╦(bi©Īo)ų«ę╗Ż¼įńŲ┌Ą─įŲėŗ╦Ńé╚(c©©)ųžė┌╗ź┬ō(li©ón)ŠW(w©Żng)æ¬(y©®ng)ė├Ż¼Ų¾śI(y©©)╝ēæ¬(y©®ng)ė├▌^╔┘ĪŻļSų°Ų¾śI(y©©)╦ĮėąįŲĖ┼─ŅĄ─░l(f©Ī)š╣Ż¼é„Įy(t©»ng)Ą─Ų¾śI(y©©)╝ēæ¬(y©®ng)ė├Å─öĄ(sh©┤)ō■(j©┤)ųąą─ĄĮųąķg╝■ĪóŠÄ│╠─Ż╩ĮĪóöĄ(sh©┤)ō■(j©┤)┤µā”ĘĮ╩ĮČ╝į┌Ž“įŲėŗ╦ŃŲĮ┼_▀węŲŻ¼┤¾┴┐Ą─Ų¾śI(y©©)╝ēĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ▀węŲĄĮįŲųąīó╩Ū╬┤üĒę╗Č╬Ģrķgā╚(n©©i)įŲėŗ╦Ń╝╝ąg(sh©┤)░l(f©Ī)š╣Ą─┌ģä▌Ż¼┼cĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņųąė÷ĄĮĄ─å¢Ņ}ŽÓŅÉ╦ŲŻ¼ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─ACID╠žąįīó╩╣Ą├įŲųąĄ─öĄ(sh©┤)ō■(j©┤)Äņ▓┐Ęų▓┘ū„ąį─▄ĮĄĄ═Ż¼Å─Ų¾śI(y©©)╝ēæ¬(y©®ng)ė├Ą─öĄ(sh©┤)ō■(j©┤)╣▄└ĒĄ─╠žąįČ°čįŻ¼į÷ĪóähĪóĖ─Īó▓ķ4éĆ╗∙▒Š▓┘ū„ųąŻ¼▓ķįāĄ─╩╣ė├Ņl┬╩Ė³×ķ’@ų°Ż¼į┌Ų¾śI(y©©)įŲ┤µā”Łh(hu©ón)Š│Ž┬ī”▓ķįā├³┴ŅĄ─╠Ä└ĒūāĄ├ų┴ĻP(gu©Īn)ųžę¬Ż¼╚ń║╬į┌ĮĄĄ═öĄ(sh©┤)ō■(j©┤)é„▌ö┬╩Ą─ŪķørŽ┬═¼ĢrØMūŃöĄ(sh©┤)ō■(j©┤)ČÓ▒Ēų«ķgĄ─ę└┘ćąį│╔×ķ▒žĒÜ┐╝æ]Ą─ĻP(gu©Īn)µIę“╦žŻ¼▒Š╬─═©▀^Ęų╬÷Ų¾śI(y©©)įŲĘ■äš(w©┤)Ą─3īė╝▄śŗ(g©░u)Ż¼į┌ŠC║Ž┐╝æ]ĻP(gu©Īn)µIę“╦žĄ─ŪķørŽ┬Ż¼ī”įŲ┤µā”ųąą─ė├æ¶▓ķįā▓┘ū„ł╠(zh©¬)ąąŪķør╠ß│÷ę╗ĘNų¦│ųīŹļHæ¬(y©®ng)ė├Ą─Ęų▓╝ĘĮ░ĖĪŻ
1 ŽÓĻP(gu©Īn)蹊┐▒│Š░
1Ż«1Ų¾śI(y©©)╦ĮėąįŲ▒│Š░
Ų¾śI(y©©)╦ĮėąįŲ╩Ūį┌Ų¾śI(y©©)ā╚(n©©i)▓┐śŗ(g©░u)Į©Ą─Ż¼╗∙ė┌Ų¾śI(y©©)ā╚(n©©i)▓┐äėæB(t©żi)śI(y©©)äš(w©┤)ūā╗»Ą─ąĶ꬯¼ī”öĄ(sh©┤)ō■(j©┤)║═Ę■äš(w©┤)įO(sh©©)ų├░▓╚½ėąą¦┐žųŲŻ¼×ķŲ¾śI(y©©)ā╚(n©©i)▓┐śI(y©©)äš(w©┤)īŹ╩®╠ß╣®Ę■äš(w©┤)ŲĮ┼_Ż¼Ųõ╗∙ĄA(ch©│)įO(sh©©)╩®┐╔įO(sh©©)┴óį┌Ų¾śI(y©©)ā╚(n©©i)▓┐╗“ų„ÖC(j©®)═ą╣▄ł÷╦∙Ż¼╦³─▄ē“×ķŲ¾śI(y©©)╣Ø(ji©”)╩Īą┼Žó╗»ķ_õNŻ¼Š▀ėąņ`╗Ņąį║═░▓╚½ąįĄ─╠ž³cŻ¼╩Ū─┐Ū░Ų¾śI(y©©)ą┼Žó╗»Ą─░l(f©Ī)š╣ĘĮŽ“Ż¼ė╔ė┌Ų¾śI(y©©)╦ĮėąįŲöĄ(sh©┤)ō■(j©┤)ųąą─┤¾▓┐ĘųĄ─öĄ(sh©┤)ō■(j©┤)Äņ├³┴Ņ▓┘ū„╩ŪöĄ(sh©┤)ō■(j©┤)▓ķįāŻ¼▒Š╬─īóÅ─öĄ(sh©┤)ō■(j©┤)▓ķįā▓┘ū„üĒČ©┴xöĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įĪŻ
1Ż«2Ų¾śI(y©©)╦ĮėąįŲ┤µā”ųąą─öĄ(sh©┤)ō■(j©┤)╣▄└Ē╝▄śŗ(g©░u)
į┌╬─½I(xi©żn)[6]Ą─╗∙ĄA(ch©│)╔ŽŻ¼▒Š╬─╠ß│÷┴╦ę╗ĘNŲ¾śI(y©©)╦ĮėąįŲ┤µā”ųąą─öĄ(sh©┤)ō■(j©┤)╣▄└Ē╝▄śŗ(g©░u)ĪŻŲ¾śI(y©©)įŲėŗ╦Ń┤µā”ųąą─▓╗═¼ė┌Ęų▓╝╩Į╝▄śŗ(g©░u)Ž┬Ą─öĄ(sh©┤)ō■(j©┤)ųąą─Ż¼╦³╠ß╣®╣½╣▓ŲĮ┼_(PAAS)śI(y©©)äš(w©┤)Ą─öĄ(sh©┤)ō■(j©┤)▓ķįā╣żū„Ż¼š{(di©żo)ė├╠ōöM╗»▓┘ū„ŽĄĮy(t©»ng)╣▄└ĒŽ┬Ą─öĄ(sh©┤)ō■(j©┤)┤µā”īėĘ■äš(w©┤)ĪŻį┌▒Š╬─Ą─蹊┐ųąŻ¼īóŲ¾śI(y©©)╦ĮėąįŲöĄ(sh©┤)ō■(j©┤)╣▄└Ē╝▄śŗ(g©░u)Ęų×ķ3īėŻ║1)Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„īėŻ╗2)öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cīėŻ╗3)▓ķįāĮY(ji©”)╣¹ģR┐éŲ„īėĪŻł╠(zh©¬)ąąĢrė├æ¶═©▀^SQL├³┴ŅįLå¢Ų¾śI(y©©)╦ĮėąįŲöĄ(sh©┤)ō■(j©┤)ųąą─╣▄└ĒŽĄĮy(t©»ng)Ż¼SQL├³┴Ņį┌Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„īė▒╗ŅA(y©┤)╠Ä└Ē│╔╚¶Ė╔ūė▓ķįā├³┴ŅŻ¼╚╗║¾Ė∙ō■(j©┤)öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įīóĖ„ūė▓ķįā├³┴Ņ░l(f©Ī)╦═ĄĮöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cDN1Ż¼DN2Ż¼?Ż¼DNNŻ¼Ė„╣Ø(ji©”)³cĮ╗╗źł╠(zh©¬)ąą├³┴ŅŻ¼ūŅ║¾ė╔▓ķįāĮY(ji©”)╣¹ģR┐éŲ„ĘĄ╗ž▓ķįāĮY(ji©”)╣¹Įoė├æ¶Ż¼Š▀¾w┴„│╠╚ńłD1╦∙╩ŠŻ║
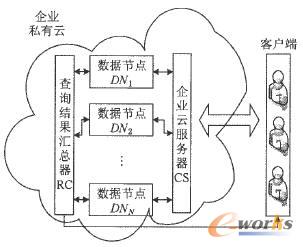
łD1 Ų¾śI(y©©)╦ĮėąįŲīė┤╬ĮY(ji©”)śŗ(g©░u)
1Ż«3öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬į
į┌Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĪó▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĄ╚Ą─蹊┐ųąęčĮø(j©®ng)╠ß│÷┴╦ČÓĘNöĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įŻ¼ų„ę¬┐╔ęįĘų×ķ╝»ųąĘų▓╝Īó╦«ŲĮĘų▓╝Īó┤╣ų▒Ęų▓╝ęį╝░╗ņ║ŽĘų▓╝Ą╚ĪŻ╝»ųąĘų▓╝╩ŪųĖöĄ(sh©┤)ō■(j©┤)Äņ▒ĒéŃ▓┐ā╚(n©©i)╚▌╝»ųą┤µā”į┌öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cŻ¼Ąõą═Ą─╦ŃĘ©ėąTogetherŻ╗╦«ŲĮĘų▓╝┐╔ęĢ×ķę╗ĘN▀xō±▓┘ū„Ż¼īóĻP(gu©Īn)ŽĄĄ─į¬ĮMäØĘų│╔▓╗═¼Ą─ūė╝»(═©│Ż×ķ▓╗ŽÓĮ╗Ą─ūė╝»)Ż¼Ęų▓╝ĄĮ▓╗═¼Ą─╣Ø(ji©”)³cŻ¼▒╚▌^Ąõą═Ą─╦«ŲĮĘų▓╝ėąRoundRobinŻ╗┤╣ų▒Ęų▓╝┐╔ęĢ×ķę╗ĘN═Čė░▓┘ū„Ż¼Å─ī┘ąį│÷░l(f©Ī)Ż¼īóĻP(gu©Īn)ŽĄĄ─ī┘ąį╝»äØĘų×ķ▓╗═¼Ą─ūė╝»▓óĘų▓╝ĄĮ▓╗═¼Ą─╣Ø(ji©”)³cŻ╗╗ņ║Ž▓┘ū„Įķė┌╦«ŲĮ║═┤╣ų▒Ęų▓╝ų«ķgĪŻ«ö(d©Īng)Ū░īŹļHæ¬(y©®ng)ė├╦«ŲĮĘų▓╝▒╚▌^ČÓŻ¼Š▀ėą║▄║├Ą─▀mæ¬(y©®ng)ąįŻ¼įŲėŗ╦ŃĄ─╠žąįų«ę╗╩Ūßśī”║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└ĒŻ¼Ų¾śI(y©©)╝ēæ¬(y©®ng)ė├ųą▓╗öÓ«a(ch©Żn)╔·┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▓óŪę╔µ╝░ĄĮ┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)Ė³ą┬Ż¼╦«ŲĮĘų▓╝Ą─╠Ä└Ē╔Žīó«a(ch©Żn)╔·ę╗Č©Ą─öĄ(sh©┤)ō■(j©┤)ę╗ų┬ąįå¢Ņ}╝░Ęų▓╝Ą─Ą³┤·å¢Ņ}Ż¼╗∙ė┌┤╦ĒŚ┐╝æ]Ż¼▒Š╬─Ą─蹊┐ųą▓╔ė├╗ņ║ŽĘų▓╝ū„×ķ│÷░l(f©Ī)³cŻ¼▓óŪę╝┘Č©▓╗═¼Ą─ūė╝»ųąĄ─ī┘ąį┐╔ęį╚▀ėÓŻ¼╝┤┤µā”į┌▓╗═¼öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─öĄ(sh©┤)ō■(j©┤)┤µį┌ųžÅ═(f©┤)Ż¼į┌┤╦╝┘įO(sh©©)Ž┬Ż¼ī”▓╗═¼öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c│ą▌d─▄┴”Ą─┐╝æ]│╔×ķ蹊┐Ą─ųžę¬ĻP(gu©Īn)ūó³cĪŻ
2 įŲ┤µā”öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĘų▓╝▓▀┬į(CSND)
2Ż«1▓▀┬įąĶ┐╝æ]ę“╦ž
į┌蹊┐╬─½I(xi©żn)ųą│ŻęŖĄ─öĄ(sh©┤)ō■(j©┤)Ęų▓╝╦╝Žļ╩Ūūį╔ŽČ°Ž┬Ż¼╝┤Å─┐═æ¶Ą─SQL├³┴Ņķ_╩╝Ęų╬÷Ż¼īóSQLĘų│╔╚¶Ė╔éĆūė├³┴Ņį┘Ęų▓╝ĄĮöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cŻ¼ł╠(zh©¬)ąąūė▓ķįā▓┘ū„Ż¼į┌įO(sh©©)ėŗĄ─▀^│╠ųąø]ėą┐╝æ]ĄĮöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c▒Š╔ĒĄ─ł╠(zh©¬)ąą─▄┴”Ż«▒Š╬─ĮY(ji©”)║Žūį╔ŽČ°Ž┬║═ūįŽ┬Č°╔Žā╔ĘNĘų▓╝╦╝ŽļŻ¼Å─┐═æ¶▌ö╚ļĄ─SQL├³┴Ņ║═öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─│ą▌d─▄┴”═¼Ģrų°╩ųŻ¼ŠC║Ž┐╝æ]öĄ(sh©┤)ō■(j©┤)▓ķįāūė├³┴ŅĄ─Ęų▓╝▓▀┬įĪŻįō▓▀┬įų„ę¬Å─ęįŽ┬3éĆĘĮ├µ┐╝æ]Ż║
2Ż«1Ż«1 SQL▓ķįā├³┴ŅĄ─ł╠(zh©¬)ąąĘČć·
┤_Č©SQL▓ķįā├³┴ŅĄ─ł╠(zh©¬)ąąĘČć·ī”Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„Ęų┼õ╠Ä└Ē┐═æ¶ųĖ┴Ņėąųžę¬ęŌ┴xĪŻ╚¶▓ķįā╩Ūį┌å╬▒ĒųąŻ¼ätų╗ąĶĘų┼õSQLūė├³┴Ņį┌║¼ėą▀@ę╗éĆ▒ĒĄ─öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cŻ╗╚ń╣¹╩ŪČÓ▒Ē┬ō(li©ón)Įė▓┘ū„Ż¼ę¬Ž╚┤_Č©╩ŪʱėąöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c═¼Ģr┤µėą▀@ā╔éĆ▒Ē┘Yį┤Ż¼╚ń╣¹ø]ėąŻ¼ätąĶę¬┼ąöÓ▓┘ū„╩Ū╚ń║╬┤_Č©─Ūā╔éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĘų┼õūė├³┴ŅŻ¼╚╗║¾▀M(j©¼n)ąąĘųäe▓ķįāĪŻ
2Ż«1Ż«2ūŅĮ³Ģrķgų▄Ų┌Ą─▓ķįā┤╬öĄ(sh©┤)
Įy(t©»ng)ėŗį┌ęÄ(gu©®)Č©Ą─▓ķįāų▄Ų┌ā╚(n©©i)▒╗įLå¢Ą─▒ĒĄ─┤╬öĄ(sh©┤)Ż¼ą╬│╔▒Ē▓ķįāŠžĻćŻ¼┤_Č©å╬▒Ē▒╗▓ķįā┤╬öĄ(sh©┤)║═ČÓ▒Ē═¼Ģr▒╗▓ķįā┤╬öĄ(sh©┤)ĪŻ┼c┤╦═¼ĢrŻ¼įO(sh©©)Č©ŅlČ╚ķōųĄŻ¼ī”▓ķįā┤╬öĄ(sh©┤)│¼▀^ķōųĄĄ─▒Ē▀M(j©¼n)ąąś╦(bi©Īo)ėø╠Ä└ĒŻ¼į┌Ęų┼õöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĢr╩╣ŲõŠ▀ėąā×(y©Łu)Ž╚Ęų┼õÖÓ(qu©ón)ĪŻ
2Ż«1Ż«3öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─├³┴Ņ╠Ä└Ē─▄┴”
╝┘įO(sh©©)├┐éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cČ╝Š▀ėąöĄ(sh©┤)ō■(j©┤)┤µā”║═ł╠(zh©¬)ąą▓ķįā├³┴ŅĄ─╣”─▄Ż¼Ųõ┤µā”║═ł╠(zh©¬)ąą─▄┴”Ą─ÖÓ(qu©ón)ųĄ┐╔ęį┤_Č©Ųõ╣”─▄Ą─ā×(y©Łu)┴ėŻ¼į┌Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„Ęų┼õūė▓ķįā├³┴ŅĢrĖ∙ō■(j©┤)öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cŪķørĘų┼õĪŻ▒Š╬─įO(sh©©)Č©öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cÖÓ(qu©ón)ųĄĄ╚╝ēėŗ╦Ń╚ń╩Į(1)╦∙╩ŠŻ¼ŲõųąöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─╠Ä└Ē─▄┴”╩ŪĖ∙ō■(j©┤)ŽĄĮy(t©»ng)┘Yį┤┴┐┤_Č©ĪŻ

1evel1×ķ╣Ø(ji©”)³cūŅā×(y©Łu)ĀŅæB(t©żi)Ż¼level2×ķ╣Ø(ji©”)³cš²│ŻĀŅæB(t©żi)Ż¼Ęų▓╝▓▀┬įīóĖ∙ō■(j©┤)╣Ø(ji©”)³c─▄┴”Ęų┼õūė▓ķįāŻ╗level3×ķŠ»ĖµĀŅæB(t©żi)Ż¼Ęų▓╝▓▀┬įīóŠ▄Į^Ęų┼õūė▓ķįāĮo╣Ø(ji©”)³cĪŻīŹ“×ųĖś╦(bi©Īo)▓╔ė├─Š═░įŁ└ĒŻ¼└²╚ńŻ║┤µā”─▄┴”Ę¹║Žę╗╝ēųĖś╦(bi©Īo)Ż¼▓ķįā─▄┴”Ę¹║ŽČ■╝ēųĖś╦(bi©Īo)Ż¼ät┤╦öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c×ķČ■╝ēųĖś╦(bi©Īo)ĪŻ
2Ż«2▓▀┬į╗∙▒Š╦╝Žļ
Å─2Ż«1╣Ø(ji©”)┐╔ęį┐┤│÷Ż¼ę¬Ė─╔ŲŽĄĮy(t©»ng)Ēææ¬(y©®ng)ą¦┬╩Ż¼╠ßĖ▀ŽĄĮy(t©»ng)▓ķįāąį─▄Ż¼ąĶ║Ž└ĒĘų┼õ├┐éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cūė▓ķįāŻ¼īó┐╔─▄│÷¼F(xi©żn)▀BĮėĄ─▒ĒųąĄ─ī┘ąį▀M(j©¼n)ąą═¼╣Ø(ji©”)³c┤µĘ┼Ż¼▀@śėį┌£p╔┘öĄ(sh©┤)ō■(j©┤)é„▌öĢrķgĄ─═¼Ģr╠ßĖ▀š¹éĆ▓ķįāų▄Ų┌ĢrķgĪŻ▒Š╬─╝┘Č©Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„īó▓ķįā├³┴Ņ▀M(j©¼n)ąąĘųĮŌĢrŻ¼ūė├³┴ŅųąūŅČÓ│÷¼F(xi©żn)ā╔éĆöĄ(sh©┤)ō■(j©┤)▒Ē▀BĮėŻ¼Ųõ╦¹Å═(f©┤)ļs▀BĮėĢ║▓╗┐╝æ]ĪŻ╦ŃĘ©╦∙ąĶģóöĄ(sh©┤)įO(sh©©)ų├╚ń▒Ē1╦∙╩ŠŻ║

▒Ē1 ŽĄĮy(t©»ng)ģóöĄ(sh©┤)┴ą▒Ē
Ž┬├µ╝┘įO(sh©©)ŽĄĮy(t©»ng)ęčėą┘Yį┤╝░ŽĄĮy(t©»ng)ģóöĄ(sh©┤)įO(sh©©)ų├╚ńŽ┬Ż║
1)Ų¾śI(y©©)╦ĮėąįŲųąöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cDN1Ż¼DN2Ż¼?Ż¼DNNŻ╗
2)┤╦╠Ä×ķöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ──▄┴”ÖÓ(qu©ón)ųĄDNCĪŻŻ¼DNCĪŻŻ¼DNC3Ż╗
3)▓ķįā├³┴ŅĮy(t©»ng)ėŗų▄Ų┌
2Ż«3╦ŃĘ©š¹¾w┴„│╠
«ö(d©Īng)Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„Įė╩šĄĮė├æ¶Ą─öĄ(sh©┤)ō■(j©┤)▓ķįā├³┴ŅĢrŻ¼╦ŃĘ©ķ_╩╝ł╠(zh©¬)ąąĪŻ╩ūŽ╚Ż¼╔·│╔öĄ(sh©┤)ō■(j©┤)Äņ▒Ē▓ķįāŠžĻć(ł╠(zh©¬)ąą╦ŃĘ©1Ą├ĄĮ)Ż¼╔·│╔Ęų▓╝▓▀┬į(ł╠(zh©¬)ąą╦ŃĘ©2Ą├ĄĮ)Ż¼╔·│╔Ęų┼õ▓▀┬į(ł╠(zh©¬)ąą╦ŃĘ©3Ą├ĄĮ)Ż╗╚╗║¾Ż¼Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„Ė∙ō■(j©┤)Ęų┼õ▓▀┬įīóöĄ(sh©┤)ō■(j©┤)▓ķįā├³┴ŅĘų┼õĮoöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cŻ¼Ė„öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cł╠(zh©¬)ąą▓ķįāūė├³┴ŅŻ¼▓óīóĮY(ji©”)╣¹é„Įo▓ķįāĮY(ji©”)╣¹ģR┐éŲ„Ż╗ūŅ║¾Ż¼▓ķįāĮY(ji©”)╣¹ģR┐éŲ„īóĮY(ji©”)╣¹ą┼Žóé„Įoė├æ¶ĪŻ
2Ż«4╦ŃĘ©─Żą═╝░īŹ¼F(xi©żn)
╦ŃĘ©1Ż«SQL▓ķįā├³┴ŅĄ─ł╠(zh©¬)ąąĘČć·Įy(t©»ng)ėŗ║═▓ķįā┤╬öĄ(sh©┤)Įy(t©»ng)ėŗĪŻ

▒Š╦ŃĘ©╝┘įO(sh©©)öĄ(sh©┤)ō■(j©┤)Äņųą├┐ā╔éĆ▒Ēų«ķgČ╝┐╔─▄░l(f©Ī)╔·▀BĮė▓┘ū„Ż¼Ė∙ō■(j©┤)ūė▓ķįā╔µ╝░Ą─öĄ(sh©┤)ō■(j©┤)▒Ēį┌öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cųą▒╗įLå¢Ą─┤╬öĄ(sh©┤)Ż¼Įy(t©»ng)ėŗą╬│╔öĄ(sh©┤)ō■(j©┤)▒Ē▓ķįāŠžĻćTaInqMatrixI-M][M+1]Ż¼ŠžĻćĄ─ąą║═┴ą╩ŪöĄ(sh©┤)ō■(j©┤)▒ĒĄ─äe├¹ĪŻ╚ń╣¹╩ŪŽÓ═¼Ą─äe├¹Ż¼┤·▒Ē┤╦▓ķįā?y©Łu)ķå╬▒Ē▓ķįāŻ╗╚ń╣¹╩Ū▓╗═¼Ą─äe├¹Ż¼┤·▒Ē▓ķįā?y©Łu)ķā╔▒Ē▀BĮė▓ķįāŻ«└²╚ńŻ║TaInqMatrix[1][1]Ą─ųĄ┤·▒Ēäe├¹×ķ1Ą─▒Ēį┌─│éĆTų▄Ų┌▀M(j©¼n)ąąĄ─▓ķįā┤╬öĄ(sh©┤)Ż¼TaInqMatrix EliE2]Ą─ųĄ┤·▒Ē▀BĮėäe├¹×ķ1Ż¼2Ą─▒Ē╩Šį┌─│éĆTų▄Ų┌Ą─▓ķįā┤╬öĄ(sh©┤)ĪŻ
į┌ł╠(zh©¬)ąą▀^╦ŃĘ©1║¾Ż¼ą╬│╔┴╦TaInqMatrix[M][M+1]ŠžĻćŻ¼▓óį┌Ą┌M+1┴ąĮy(t©»ng)ėŗ┴╦├┐éĆöĄ(sh©┤)ō■(j©┤)▒ĒĄ─į┌─│ę╗éĆTų▄Ų┌Ą─┐é▓ķįā┤╬öĄ(sh©┤)ĪŻĮėŽ┬üĒ╦ŃĘ©2īóĖ∙ō■(j©┤)┤╦ŠžĻćĄ─ųĄ╩Ūʱ│¼▀^ęÄ(gu©®)Č©ķōųĄ(Ė∙ō■(j©┤)ŽĄĮy(t©»ng)▀\ąąŪķørįO(sh©©)ų├)Ż¼░┤▓ķįāĄ─▀BĮė▒Ēā×(y©Łu)Ž╚įŁät░č▒Ēäe├¹ĮMĘ┼╚ļĄĮĘų▓╝ĻĀ┴ąųąĪŻį┌╦ŃĘ©ł╠(zh©¬)ąąĮY(ji©”)╩°Ż¼īóą╬│╔ČĪų▄Ų┌ā╚(n©©i)Ą─▓ķįāĘų▓╝ĻĀ┴ąĪŻ╦ŃĘ©Ą─ł╠(zh©¬)ąąęįtablePairŻ«next()║═singleTableŻ«next()║»öĄ(sh©┤)üĒĘųäe½@╚ĪŽ┬ę╗éĆ▀BĮė▓┘ū„Ą─▒Ēäe├¹ĮMųĄ║═å╬▒Ē▓┘ū„Ą─öĄ(sh©┤)ō■(j©┤)▒Ēäe├¹ųĄŻ¼Š▀¾w╦ŃĘ©╚ńŽ┬Ż║
╦ŃĘ©2Ż«ą╬│╔Ęų▓╝ĻĀ┴ąĪŻ


╦ŃĘ©3▌ö│÷×ķĘų▓╝▓▀┬įŻ¼ųŲČ©▒Š▓▀┬įų„ę¬┐╝æ]ę“╦ž╚ńŽ┬Ż║
1)öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c«ö(d©Īng)Ū░ĀŅæB(t©żi)
ė╔ė┌öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─«ö(d©Īng)Ū░ł╠(zh©¬)ąą─▄┴”Ģ■Ė∙ō■(j©┤)įO(sh©©)Č©Ą─ųĖś╦(bi©Īo)ųĄŻ¼Č©Ų┌▒╗ś╦(bi©Īo)ėøĪŻ╦∙ęįį┌╦ŃĘ©3ł╠(zh©¬)ąąĮY(ji©”)╩°║¾ę¬ą▐Ė─öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─«ö(d©Īng)Ū░ĀŅæB(t©żi)ĪŻDnŻ«queryActual▒Ē╩Š╣Ø(ji©”)³cĄ─«ö(d©Īng)Ū░ł╠(zh©¬)ąą─▄┴”║»öĄ(sh©┤)Ż¼į┌öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ├ĄĮę╗┤╬ūė▓ķįāĘų┼õ║¾Ż¼DnŻ«queryActualł╠(zh©¬)ąą╝ė▓┘ū„Ż¼▀@śėŽ┬ę╗▌åĮy(t©»ng)ėŗųąŻ¼öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c╩ŻėÓł╠(zh©¬)ąą─▄┴”Ą╚╝ēĀŅæB(t©żi)Ģ■▒Ż│ųĖ³ą┬ĪŻ
2)Ęų▓╝▓▀┬į┐╝æ]öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c«ö(d©Īng)Ū░Ą─┤µā”Ūķør
╚ń╣¹«ö(d©Īng)Ū░Ą─ūė▓ķįā├³┴Ņ╔µ╝░ĄĮ┴╦ā╔▒Ē▀BĮėĄ─ĀŅørŻ¼╩ūŽ╚Å─öĄ(sh©┤)ō■(j©┤)Ęų▓╝ĻĀ┴ąųą╚Ī│÷öĄ(sh©┤)ō■(j©┤)▒Ēäe├¹ųĄŻ¼╚╗║¾Å─«ö(d©Īng)Ū░öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cųą▒ķÜv▓ķįā┤µā”ėą▀@ā╔éĆöĄ(sh©┤)ō■(j©┤)▒ĒĄ─╣Ø(ji©”)³cŻ¼═©▀^║»öĄ(sh©┤)getFromDN()ą╬│╔list()ĻĀ┴ąŻ¼į┘ųéĆ┼ąöÓöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĀŅæB(t©żi)Ż¼Ęų┼õūė▓ķįāĪŻ
3Ęų╬÷īŹ“×
▒Š╬─Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬į┐╝æ]┴╦ė├æ¶sQL▓ķįā├³┴ŅĄ─Ęų┼õ║═öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─╠Ä└Ē─▄┴”ā╔éĆĘĮ├µĄ─ę“╦žŻ¼ą╬│╔┴╦įŲėŗ╦ŃŁh(hu©ón)Š│Ž┬įŲ┤µā”ųąą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įĪŻ╦ŃĘ©ł╠(zh©¬)ąąĮY(ji©”)╩°Ų¾śI(y©©)įŲĘ■äš(w©┤)Ų„┐╔Ė∙ō■(j©┤)DNplanüĒ▀M(j©¼n)ąąSQLūė├³┴ŅĄ─Ęų┼õŻ¼╠ßĖ▀┴╦Ęų┼õĄ─▀mæ¬(y©®ng)ąįŻ¼▓▀┬įĄ─Ė─▀M(j©¼n)¾w¼F(xi©żn)į┌ęįŽ┬ā╔éĆĘĮ├µŻ║
1)Ė─ūā┴╦╣Ø(ji©”)³cĘų┼õ▓╗┐╝æ]öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c╠Ä└Ē─▄┴”Ż¼ų╗ĻP(gu©Īn)ūóūį╔ŽČ°Ž┬ĘųĮŌĄ─Ęų┼õ╦╝ŽļŻ╗
2)Ė∙ō■(j©┤)╣Ø(ji©”)³cĄ─╠Ä└Ē─▄┴”Ż¼Ęų┼õČÓ▒ĒĄĮę╗éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cŻ¼┐╝æ]┴╦öĄ(sh©┤)ō■(j©┤)Äņ▀BĮė▓ķįāĄ─ŪķørĪŻ
ė╔ė┌śŗ(g©░u)Į©Ų¾śI(y©©)╦ĮėąįŲĒŚ─┐▀Ć╬┤ØMūŃīŹ“׹ĶŪ¾Ż¼ę“┤╦īŹ“×įO(sh©©)ėŗ╩╣ė├ę╗┼_PCū„×ķŲ¾śI(y©©)įŲĘ■äš(w©┤)Ų„(2Ż«0 GCPUŻ¼4GBā╚(n©©i)┤µŻ¼Ubuntu▓┘ū„ŽĄĮy(t©»ng))Ż¼┴Ē═Ō╩╣ė├3┼_PCū„×ķöĄ(sh©┤)ō■(j©┤)┤µā”╣Ø(ji©”)³c(ę╗┼_×ķ2Ż«0 G CPUŻ¼2 GBā╚(n©©i)┤µŻ¼Ubuntu▓┘ū„ŽĄĮy(t©»ng)Ż¼┴Ē═Ōā╔┼_×ķ1Ż«0G CPUŻ¼1GBā╚(n©©i)┤µŻ¼Ubuntu▓┘ū„ŽĄĮy(t©»ng))Ż«ĻP(gu©Īn)ė┌3Ż«1Ż«3╣Ø(ji©”)╠ߥĮĄ─öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cÖÓ(qu©ón)ųĄĄ╚╝ēįO(sh©©)ų├Ż¼▒ŠīŹ“×öMįO(sh©©)3╝ēś╦(bi©Īo)£╩(zh©│n)Š▀¾wųĖś╦(bi©Īo)╚ń▒Ē2╦∙╩ŠŻ║

▒Ē2öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c3╝ēÖÓ(qu©ón)ųĄś╦(bi©Īo)£╩(zh©│n)
īŹ“×ķ_╩╝ĢrŻ¼ų„Ę■äš(w©┤)Ų„ėŗ╦Ń╣Ø(ji©”)³cĄ─ųĖś╦(bi©Īo)Ą╚╝ē┤_Č©║¾Ż¼īósQLĘųĮŌ│╔ūė├³┴ŅŻ¼░┤CSND▓▀┬į▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų▓╝ĪŻ┤²öĄ(sh©┤)ō■(j©┤)Ęų▓╝═Ļ│╔║¾Ż¼į┌ų„Ę■äš(w©┤)Ų„╔Ž▀M(j©¼n)ąą▓ķįā║═ģR┐éŻ¼▒╚▌^öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įį┌I▓╗═¼öĄ(sh©┤)ō■(j©┤)┴┐ĢröĄ(sh©┤)ō■(j©┤)ÄņĄ─▓ķįāĒææ¬(y©®ng)ĢrķgĪŻīŹ“×ųąī”▒╚┴╦╝»ųą┤µā”(together)Īó▌å▐D(zhu©Żn)äØĘų(round robin)║═öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĘų▓╝äØĘų(CSND)ĪŻĮY(ji©”)╣¹╚ńłD2ĪółD3╦∙╩ŠĪŻłDųąÖM▌S×ķöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cå╬▒Ē▓ķįāĄ─öĄ(sh©┤)ō■(j©┤)┴┐Ż¼ęį100M×ķå╬╬╗Ż╗┐v▌S×ķ▓ķįāĒææ¬(y©®ng)ĢrķgŻ¼ęįms×ķå╬╬╗ĪŻ
Å─łD2ųą┐╔ęį├„’@┐┤│÷Ż¼CSNDĘų▓╝▓▀┬įī”ė┌öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cå╬▒Ē▓ķįāĄ─Ę┤æ¬(y©®ng)ā×(y©Łu)ė┌Together║═RoundRobinĘų▓╝▓▀┬įŻ¼Ė∙ō■(j©┤)öĄ(sh©┤)ō■(j©┤)┴┐Ą─į÷╝ėŻ¼▀@ĘNā×(y©Łu)ä▌Ė³×ķ├„’@ĪŻ
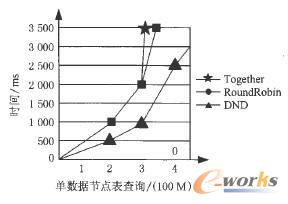
łD2öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cå╬▒Ē▓ķįāĢrķgĮy(t©»ng)ėŗłD
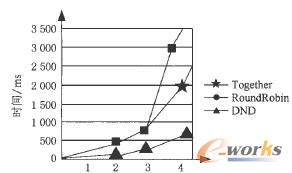
łD3öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cČÓ▒Ē▓ķįāĢrķgĮy(t©»ng)ėŗłD
Ė∙ō■(j©┤)öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─╠Ä└Ē─▄┴”ĘųŻ¼┼õĄ─Ė„öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cå╬▒Ē▓ķįā├³┴ŅŻ¼¤oąĶį┌ŽĄĮy(t©»ng)ā╚(n©©i)▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)é„▌öŻ¼ų╗ąĶįLå¢å╬éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cŻ¼┤¾┤¾╣Ø(ji©”)╩Ī┴╦ŽĄĮy(t©»ng)Ēææ¬(y©®ng)ĢrķgĪŻīŹ“×ĮY(ji©”)šōŻ║Ė─ūā║¾Ą─▓▀┬įŠ▀ėą┴╝║├Ą─▀mæ¬(y©®ng)ąįŻ¼─▄ē“Ė─╔ŲįŲėŗ╦ŃŽĄĮy(t©»ng)Ą─SQLė├æ¶▓ķįāŁh(hu©ón)Š│ĪŻ
å╬▒Ē▓ķįā─▄┴”Ą─┐ņ┬²╩ŪŲ¾śI(y©©)įŲėŗ╦ŃĒææ¬(y©®ng)ĢrķgĄ─ųžę¬£y┴┐ųĖś╦(bi©Īo)ĪŻCSNDĘų▓╝▓▀┬į×ķŲ¾śI(y©©)įŲėŗ╦ŃöĄ(sh©┤)ō■(j©┤)╠Ä└Ē£p╔┘┴╦Ēææ¬(y©®ng)ĢrķgĪŻ
Å─łD3┐╔ęį┐┤│÷Ż¼į┌▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cČÓ▒Ē▓ķįāĢrŻ¼╚į╩ŪCSNDĘų▓╝▓▀┬įš╝ā×(y©Łu)ä▌Ż¼ČÓ▒Ē▓ķįāöĄ(sh©┤)ō■(j©┤)┴┐Ą─į÷╝ėā×(y©Łu)ä▌įĮüĒįĮ├„’@ĪŻīŹ“×ĮY(ji©”)šōŻ║ī”ė┌ČÓ▒Ē▓ķįāCSNDĘų▓╝▓▀┬įŻ¼│õĘų┐╝æ]öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cöĄ(sh©┤)ō■(j©┤)▒ĒĄ─Ęų▓╝ŪķørŻ¼Ė³┤¾Ąž£p╔┘┴╦öĄ(sh©┤)ō■(j©┤)é„▌öŻ¼öĄ(sh©┤)ō■(j©┤)▒Ē═Čė░Īó▀xō±Ą╚▓┘ū„Ą─Ę┤æ¬(y©®ng)ĢrķgĪŻ
4 ŽÓĻP(gu©Īn)蹊┐¼F(xi©żn)ĀŅ
ĻP(gu©Īn)ė┌öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įć°ā╚(n©©i)═ŌėąįSČÓīW(xu©”)š▀ī”┤╦▀M(j©¼n)ąą┴╦蹊┐ĪŻįńŲ┌Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬į▌^ČÓĄ─│╔╣¹╩Ūį┌Ęų▓╝╩Į║═ŠW(w©Żng)Ė±Łh(hu©ón)Š│Ž┬░┤╣■ŽŻĪóĘČć·Īó▌å▐D(zhu©Żn)▀M(j©¼n)ąąäØĘųĄ─Ż¼║¾Ų┌▀M(j©¼n)ąąę╗Č©Ą─Ė─▀M(j©¼n)ĪŻŲõųąŻ¼░┤Ęų┼õĄ─╦╝Žļ▀M(j©¼n)ąąĘųŅÉŻ¼▓╔ė├ūį╔ŽČ°Ž┬Ęų┼õ▓▀┬įĄ─ėąŻ║ū¾└¹įŲĄ╚╚╦Å─öĄ(sh©┤)ō■(j©┤)Äņ▀B└m(x©┤)ūx╚Ī╠žąį╚╦╩ųŻ¼ĮŌøQ┴╦įŲėŗ╦Ńųąėą▓┐ĘųŽĄĮy(t©»ng)┘Yį┤ķeų├Ą─å¢Ņ}Ż╗╬─½I(xi©żn)[12]┐╝æ]┴╦į┌ČÓöĄ(sh©┤)ō■(j©┤)ųąą─Łh(hu©ón)Š│Ą─ČÓ▒Ē▀BĮė▓ķįāŻ¼╚ń║╬╠ßĖ▀öĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ąį─▄Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įĪŻ
į┌įŲėŗ╦ŃĄ─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬į╔ŽŻ¼╬─½I(xi©żn)E12]╠ß│÷┴╦ę╗ĘN├µŽ“▓ķįāöĄ(sh©┤)ō■(j©┤)ÄņöĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įŻ¼ū„š▀Ą─蹊┐╦╝┬Ęī”╬ęéāėąę╗Č©Ą─åó░l(f©Ī)Ż¼Ą½╩Ū▓╔ė├Ą─╩Ūūį╔ŽČ°Ž┬Ą─å╬ę╗╦«ŲĮĘų▓╝Ą─╗∙▒Š▓▀┬įŻ¼ø]ėą┐╝æ]öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─│ą▌d─▄┴”Ż╗╬─½I(xi©żn)蹊┐Ą─╩Ū╔ńģ^(q©▒)įŲŁh(hu©ón)Š│Ž┬Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝╝░╦č╦„▓▀┬įŻ¼╔ńģ^(q©▒)įŲ▒Š┘|(zh©¼)╔Ž╩ŪŲ¾śI(y©©)╦ĮėąįŲĄ─ę╗ĘN▒Ē¼F(xi©żn)ą╬╩ĮŻ¼ū„š▀Ą─蹊┐³c┴óūŃė┌SaaSīė├µĄ─śI(y©©)äš(w©┤)öĄ(sh©┤)ō■(j©┤)╦č╦„Ż¼ęįįŲųąĘ■äš(w©┤)╣Ø(ji©”)³cĄ─WebĘ■äš(w©┤)×ķöĄ(sh©┤)ō■(j©┤)ī”Ž¾Ż¼ėæšō╠ōöM╗»öĄ(sh©┤)ō■(j©┤)╦č╦„Ę■äš(w©┤)Ą─īŹ¼F(xi©żn)ĘĮĘ©Ż╗╬─½I(xi©żn)[14]┐╝æ]┴╦öĄ(sh©┤)ō■(j©┤)┤µā”╣Ø(ji©”)³cĄ─│ą▌d─▄┴”å¢Ņ}Ż¼ī”«Éśŗ(g©░u)╝»╚║ųąĖ∙ō■(j©┤)▓╗═¼╣Ø(ji©”)³cėŗ╦ŃÖÓ(qu©ón)ųĄ▀M(j©¼n)ąą┴╦ĘŪŠ∙ä“Ą─öĄ(sh©┤)ō■(j©┤)äØĘųŻ¼▓óī”é„Įy(t©»ng)Ą─Range╦«ŲĮĘų▓╝▀M(j©¼n)ąą┴╦Ė─▀M(j©¼n)ĪŻ
▒Š╬─╠ß│÷Ą─╩Ūį┌┤╣ų▒ĪóĘŪŠ∙ä“Ęų▓╝Ą─╗∙ĄA(ch©│)╔ŽŻ¼ßśī”ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņSQL▓ķįā▓┘ū„įO(sh©©)ėŗĄ─ę╗ĘNą┬Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝╦╝ŽļŻ¼┐╝æ]┴╦ūį╔ŽČ°Ž┬║═ūįŽ┬Č°╔ŽĄ─ĮY(ji©”)║Ž╩ĮĘų┼õ▓▀┬įĪŻ═©▀^Ęų╬÷öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─╠Ä└Ē─▄┴”Ż¼×ķūė▓ķįā├³┴ŅĘų┼õū„ģó┐╝ĪŻīŹ“×ūC├„Ż¼▀@ĘN▓▀┬įŠ▀ėąĖ³Ė▀Ą─▀mæ¬(y©®ng)ąįŻ¼├„’@╠ßĖ▀▓ķįā▓┘ū„Ą─Ēææ¬(y©®ng)╦┘┬╩ĪŻ
5 ┐éĮY(ji©”)
▒Š╬─Å─Ų¾śI(y©©)╦ĮėąįŲĄ─Łh(hu©ón)Š││÷░l(f©Ī)Ż¼ęį┤╣ų▒ĘŪŠ∙ä“Ęų▓╝×ķ╗∙ĄA(ch©│)Ż¼┐╝æ]┴╦įŲėŗ╦Ń╣Ø(ji©”)³c│ą▌d─▄┴”ÖÓ(qu©ón)ųĄŻ¼įO(sh©©)ėŗ┴╦ę╗éĆŠC║Ž┐╝æ]ūį╔ŽČ°Ž┬║═ūįŽ┬Č°╔ŽĄ─├µŽ“įŲ┤µā”æ¬(y©®ng)ė├Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įŻ¼Ė∙ō■(j©┤)Ų¾śI(y©©)įŲ┤µā”ųąą─Ą─īŹļHæ¬(y©®ng)ė├─Ż╩Į▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų▓╝Ż¼Ė∙ō■(j©┤)æ¬(y©®ng)ė├Ņl┬╩Ęų▓╝öĄ(sh©┤)ō■(j©┤)▒ĒĄĮĖ„éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c╔ŽŻ¼═¼Ģr×ķ┴╦ØMūŃöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ─ł╠(zh©¬)ąą─▄┴”Ż¼īóĖ∙ō■(j©┤)įLå¢Ņl┬╩┤Ņ┼õöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĄ──▄┴”ĪŻ═©▀^Ęų╬÷╝░įć“×ĮY(ji©”)╣¹ūC├„Ż¼▒Š╬─Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬į┐╔ęį├„’@£p╔┘öĄ(sh©┤)ō■(j©┤)Äņ▓ķįāĒææ¬(y©®ng)ĢrķgŻ¼ėąą¦╠ßĖ▀Ų¾śI(y©©)╦ĮėąįŲįLå¢ą¦┬╩ĪŻ
Ž┬ę╗▓Į╣żū„Ą─ųž³cį┌ė┌蹊┐┐╔─▄«a(ch©Żn)╔·Ą─öĄ(sh©┤)ō■(j©┤)āAą▒ĮŌøQ▐kĘ©╝░įL墤߳cĄ─öĄ(sh©┤)ō■(j©┤)▀węŲ╦ŃĘ©Ą╚ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.kaqidy.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║ę╗ĘN├µŽ“Ų¾śI(y©©)╦ĮėąįŲĄ─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬į
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.kaqidy.com/html/consultation/1083948162.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")